Rough set
In computer science, a rough set, first described by a Polish computer scientist Zdzisław I. Pawlak, is a formal approximation of a crisp set (i.e., conventional set) in terms of a pair of sets which give the lower and the upper approximation of the original set. In the standard version of rough set theory (Pawlak 1991), the lower- and upper-approximation sets are crisp sets, but in other variations, the approximating sets may be fuzzy sets.
Contents |
Definitions
This section contains an explanation of the basic framework of rough set theory (proposed originally by Zdzisław I. Pawlak), along with some of the key definitions.
Information system framework
Let 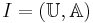 be an information system (attribute-value system), where
be an information system (attribute-value system), where 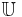 is a non-empty set of finite objects (the universe) and
is a non-empty set of finite objects (the universe) and 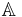 is a non-empty, finite set of attributes such that
is a non-empty, finite set of attributes such that 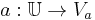 for every
for every 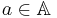 .
. 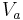 is the set of values that attribute
is the set of values that attribute 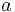 may take. The information table assigns a value
may take. The information table assigns a value 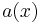 from to each attribute and object
from to each attribute and object  in the universe .
in the universe .
With any 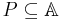 there is an associated equivalence relation
there is an associated equivalence relation 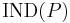 :
:
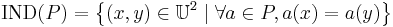
The relation is called a 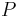 -indiscernibility relation. The partition of is a family of all equivalence classes of and is denoted by
-indiscernibility relation. The partition of is a family of all equivalence classes of and is denoted by 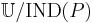 (or
(or 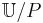 ).
).
If 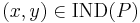 , then and
, then and 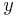 are indiscernible (or indistinguishable) by attributes from .
are indiscernible (or indistinguishable) by attributes from .
Example: equivalence-class structure
For example, consider the following information table:
-
Sample Information System Object 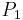
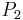
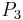
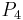
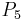
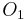
1 2 0 1 1 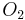
1 2 0 1 1 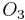
2 0 0 1 0 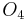
0 0 1 2 1 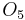
2 1 0 2 1 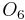
0 0 1 2 2 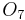
2 0 0 1 0 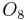
0 1 2 2 1 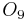
2 1 0 2 2 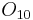
2 0 0 1 0
When the full set of attributes 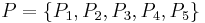 is considered, we see that we have the following seven equivalence classes:
is considered, we see that we have the following seven equivalence classes:
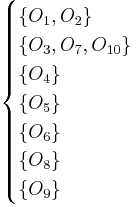
Thus, the two objects within the first equivalence class, 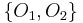 , cannot be distinguished from one another based on the available attributes, and the three objects within the second equivalence class,
, cannot be distinguished from one another based on the available attributes, and the three objects within the second equivalence class, 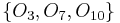 , cannot be distinguished from one another based on the available attributes. The remaining five objects are each discernible from all other objects. The equivalence classes of the -indiscernibility relation are denoted
, cannot be distinguished from one another based on the available attributes. The remaining five objects are each discernible from all other objects. The equivalence classes of the -indiscernibility relation are denoted ![[x]_P](/2012-wikipedia_en_all_nopic_01_2012/I/5716347ab104065a9ec16d77ec9c6b62.png) .
.
It is apparent that different attribute subset selections will in general lead to different indiscernibility classes. For example, if attribute  alone is selected, we obtain the following, much coarser, equivalence-class structure:
alone is selected, we obtain the following, much coarser, equivalence-class structure:
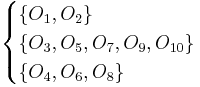
Definition of a rough set
Let 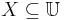 be a target set that we wish to represent using attribute subset ; that is, we are told that an arbitrary set of objects
be a target set that we wish to represent using attribute subset ; that is, we are told that an arbitrary set of objects 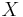 comprises a single class, and we wish to express this class (i.e., this subset) using the equivalence classes induced by attribute subset . In general, cannot be expressed exactly, because the set may include and exclude objects which are indistinguishable on the basis of attributes .
comprises a single class, and we wish to express this class (i.e., this subset) using the equivalence classes induced by attribute subset . In general, cannot be expressed exactly, because the set may include and exclude objects which are indistinguishable on the basis of attributes .
For example, consider the target set 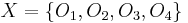 , and let attribute subset , the full available set of features. It will be noted that the set cannot be expressed exactly, because in
, and let attribute subset , the full available set of features. It will be noted that the set cannot be expressed exactly, because in ![[x]_P,](/2012-wikipedia_en_all_nopic_01_2012/I/4b2ce85c6c6b6e44983871c5a57b580b.png) , objects are indiscernible. Thus, there is no way to represent any set which includes but excludes objects and .
, objects are indiscernible. Thus, there is no way to represent any set which includes but excludes objects and .
However, the target set can be approximated using only the information contained within by constructing the -lower and -upper approximations of :
![{\underline P}X= \{x \mid [x]_P \subseteq X\}](/2012-wikipedia_en_all_nopic_01_2012/I/e4f4ec93ab81c92a337b3aa636e65e54.png)
![{\overline P}X = \{x \mid [x]_P \cap X \neq \emptyset \}](/2012-wikipedia_en_all_nopic_01_2012/I/b88264ed716b07d8885f3ddef897e54a.png)
Lower approximation and positive region
The -lower approximation, or positive region, is the union of all equivalence classes in which are contained by (i.e., are subsets of) the target set – in the example, 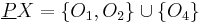 , the union of the two equivalence classes in which are contained in the target set. The lower approximation is the complete set of objects in that can be positively (i.e., unambiguously) classified as belonging to target set .
, the union of the two equivalence classes in which are contained in the target set. The lower approximation is the complete set of objects in that can be positively (i.e., unambiguously) classified as belonging to target set .
Upper approximation and negative region
The -upper approximation is the union of all equivalence classes in which have non-empty intersection with the target set – in the example, 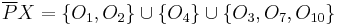 , the union of the three equivalence classes in that have non-empty intersection with the target set. The upper approximation is the complete set of objects that in that cannot be positively (i.e., unambiguously) classified as belonging to the complement (
, the union of the three equivalence classes in that have non-empty intersection with the target set. The upper approximation is the complete set of objects that in that cannot be positively (i.e., unambiguously) classified as belonging to the complement (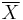 ) of the target set . In other words, the upper approximation is the complete set of objects that are possibly members of the target set .
) of the target set . In other words, the upper approximation is the complete set of objects that are possibly members of the target set .
The set 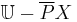 therefore represents the negative region, containing the set of objects that can be definitely ruled out as members of the target set.
therefore represents the negative region, containing the set of objects that can be definitely ruled out as members of the target set.
Boundary region
The boundary region, given by set difference 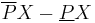 , consists of those objects that can neither be ruled in nor ruled out as members of the target set .
, consists of those objects that can neither be ruled in nor ruled out as members of the target set .
In summary, the lower approximation of a target set is a conservative approximation consisting of only those objects which can positively be identified as members of the set. (These objects have no indiscernible "clones" which are excluded by the target set.) The upper approximation is a liberal approximation which includes all objects that might be members of target set. (Some objects in the upper approximation may not be members of the target set.) From the perspective of , the lower approximation contains objects that are members of the target set with certainty (probability = 1), while the upper approximation contains objects that are members of the target set with non-zero probability (probability > 0).
The rough set
The tuple 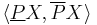 composed of the lower and upper approximation is called a rough set; thus, a rough set is composed of two crisp sets, one representing a lower boundary of the target set , and the other representing an upper boundary of the target set .
composed of the lower and upper approximation is called a rough set; thus, a rough set is composed of two crisp sets, one representing a lower boundary of the target set , and the other representing an upper boundary of the target set .
The accuracy of the rough-set representation of the set can be given (Pawlak 1991) by the following:
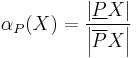
That is, the accuracy of the rough set representation of , 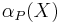 ,
,  , is the ratio of the number of objects which can positively be placed in to the number of objects that can possibly be placed in – this provides a measure of how closely the rough set is approximating the target set. Clearly, when the upper and lower approximations are equal (i.e., boundary region empty), then
, is the ratio of the number of objects which can positively be placed in to the number of objects that can possibly be placed in – this provides a measure of how closely the rough set is approximating the target set. Clearly, when the upper and lower approximations are equal (i.e., boundary region empty), then  , and the approximation is perfect; at the other extreme, whenever the lower approximation is empty, the accuracy is zero (regardless of the size of the upper approximation).
, and the approximation is perfect; at the other extreme, whenever the lower approximation is empty, the accuracy is zero (regardless of the size of the upper approximation).
Formal properties of rough sets
The important formal properties of rough sets and boundaries are given in Pawlak (1991), and the other sources cited by that book.
Definability
In general, the upper and lower approximations are not equal; in such cases, we say that target set is undefinable or roughly definable on attribute set . When the upper and lower approximations are equal (i.e., the boundary is empty),  , then the target set is definable on attribute set . We can distinguish the following special cases of undefinability:
, then the target set is definable on attribute set . We can distinguish the following special cases of undefinability:
- Set is internally undefinable if
 and
and 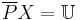 . This means that on attribute set , there are objects which we can be certain belong to target set , but there are no objects which we can definitively exclude from set .
. This means that on attribute set , there are objects which we can be certain belong to target set , but there are no objects which we can definitively exclude from set .
- Set is externally undefinable if
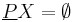 and
and 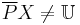 . This means that on attribute set , there are no objects which we can be certain belong to target set , but there are objects which we can definitively exclude from set .
. This means that on attribute set , there are no objects which we can be certain belong to target set , but there are objects which we can definitively exclude from set .
- Set is totally undefinable if and . This means that on attribute set , there are no objects which we can be certain belong to target set , and there are no objects which we can definitively exclude from set . Thus, on attribute set , we cannot decide whether any object is, or is not, a member of .
Reduct and core
An interesting question is whether there are attributes in the information system (attribute-value table) which are more important to the knowledge represented in the equivalence class structure than other attributes. Often, we wonder whether there is a subset of attributes which can, by itself, fully characterize the knowledge in the database; such an attribute set is called a reduct.
Formally, a reduct is a subset of attributes 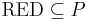 such that
such that
![[x]_{\mathrm{RED}}](/2012-wikipedia_en_all_nopic_01_2012/I/73eaf34c3ce3fa25f830b13b74825f93.png) = , that is, the equivalence classes induced by the reduced attribute set
= , that is, the equivalence classes induced by the reduced attribute set 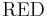 are the same as the equivalence class structure induced by the full attribute set .
are the same as the equivalence class structure induced by the full attribute set .
- the attribute set is minimal, in the sense that
![[x]_{(\mathrm{RED}-\{a\})} \neq [x]_P](/2012-wikipedia_en_all_nopic_01_2012/I/2dfaba469477c41fa58ad8eab9b45308.png) for any attribute
for any attribute 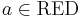 ; in other words, no attribute can be removed from set without changing the equivalence classes .
; in other words, no attribute can be removed from set without changing the equivalence classes .
A reduct can be thought of as a sufficient set of features – sufficient, that is, to represent the category structure. In the example table above, attribute set 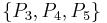 is a reduct – the information system projected on just these attributes possesses the same equivalence class structure as that expressed by the full attribute set:
is a reduct – the information system projected on just these attributes possesses the same equivalence class structure as that expressed by the full attribute set:
Attribute set is a legitimate reduct because eliminating any of these attributes causes a collapse of the equivalence-class structure, with the result that ![[x]_{\mathrm{RED}} \neq [x]_P](/2012-wikipedia_en_all_nopic_01_2012/I/797eda0d5d141d7dc7e086d3f29caae2.png) .
.
The reduct of an information system is not unique: there may be many subsets of attributes which preserve the equivalence-class structure (i.e., the knowledge) expressed in the information system. In the example information system above, another reduct is 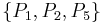 , producing the same equivalence-class structure as .
, producing the same equivalence-class structure as .
The set of attributes which is common to all reducts is called the core: the core is the set of attributes which is possessed by every legitimate reduct, and therefore consists of attributes which cannot be removed from the information system without causing collapse of the equivalence-class structure. The core may be thought of as the set of necessary attributes – necessary, that is, for the category structure to be represented. In the example, the only such attribute is 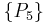 ; any one of the other attributes can be removed singly without damaging the equivalence-class structure, and hence these are all dispensable. However, removing by itself does change the equivalence-class structure, and thus is the indispensable attribute of this information system, and hence the core.
; any one of the other attributes can be removed singly without damaging the equivalence-class structure, and hence these are all dispensable. However, removing by itself does change the equivalence-class structure, and thus is the indispensable attribute of this information system, and hence the core.
It is possible for the core to be empty, which means that there is no indispensable attribute: any single attribute in such an information system can be deleted without altering the equivalence-class structure. In such cases, there is no essential or necessary attribute which is required for the class structure to be represented.
Attribute dependency
One of the most important aspects of database analysis or data acquisition is the discovery of attribute dependencies; that is, we wish to discover which variables are strongly related to which other variables. Generally, it is these strong relationships that will warrant further investigation, and that will ultimately be of use in predictive modeling.
In rough set theory, the notion of dependency is defined very simply. Let us take two (disjoint) sets of attributes, set and set 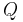 , and inquire what degree of dependency obtains between them. Each attribute set induces an (indiscernibility) equivalence class structure, the equivalence classes induced by given by , and the equivalence classes induced by given by
, and inquire what degree of dependency obtains between them. Each attribute set induces an (indiscernibility) equivalence class structure, the equivalence classes induced by given by , and the equivalence classes induced by given by ![[x]_Q](/2012-wikipedia_en_all_nopic_01_2012/I/3b9507d0bae73bfa94a8bd0b783833ae.png) .
.
Let ![[x]_Q = \{Q_1, Q_2, Q_3, \dots, Q_N \}](/2012-wikipedia_en_all_nopic_01_2012/I/b03ce9010a3171d836f83f57f1a5ccfc.png) , where
, where 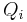 is a given equivalence class from the equivalence-class structure induced by attribute set . Then, the dependency of attribute set on attribute set ,
is a given equivalence class from the equivalence-class structure induced by attribute set . Then, the dependency of attribute set on attribute set , 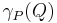 , is given by
, is given by
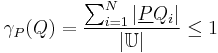
That is, for each equivalence class in , we add up the size of its lower approximation by the attributes in , i.e., 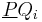 . This approximation (as above, for arbitrary set ) is the number of objects which on attribute set can be positively identified as belonging to target set . Added across all equivalence classes in , the numerator above represents the total number of objects which – based on attribute set – can be positively categorized according to the classification induced by attributes . The dependency ratio therefore expresses the proportion (within the entire universe) of such classifiable objects. The dependency "can be interpreted as a proportion of such objects in the information system for which it suffices to know the values of attributes in to determine the values of attributes in ".
. This approximation (as above, for arbitrary set ) is the number of objects which on attribute set can be positively identified as belonging to target set . Added across all equivalence classes in , the numerator above represents the total number of objects which – based on attribute set – can be positively categorized according to the classification induced by attributes . The dependency ratio therefore expresses the proportion (within the entire universe) of such classifiable objects. The dependency "can be interpreted as a proportion of such objects in the information system for which it suffices to know the values of attributes in to determine the values of attributes in ".
Another, intuitive, way to consider dependency is to take the partition induced by Q as the target class C, and consider P as the attribute set we wish to use in order to "re-construct" the target class C. If P can completely reconstruct C, then Q depends totally upon P; if P results in a poor and perhaps a random reconstruction of C, then Q does not depend upon P at all.
Thus, this measure of dependency expresses the degree of functional (i.e., deterministic) dependency of attribute set on attribute set ; it is not symmetric. The relationship of this notion of attribute dependency to more traditional information-theoretic (i.e., entropic) notions of attribute dependence has been discussed in a number of sources (e.g., Pawlak, Wong, & Ziarko 1988; Yao & Yao 2002; Wong, Ziarko, & Ye 1986).
Rule extraction
The category representations discussed above are all extensional in nature; that is, a category or complex class is simply the sum of all its members. To represent a category is, then, just to be able to list or identify all the objects belonging to that category. However, extensional category representations have very limited practical use, because they provide no insight for deciding whether novel (never-before-seen) objects are members of the category.
What is generally desired is an intentional description of the category, a representation of the category based on a set of rules that describe the scope of the category. The choice of such rules is not unique, and therein lies the issue of inductive bias. See Version space and Model selection for more about this issue.
There is a few rule-extraction methods. We will start from a rule-extraction procedure based on Ziarko & Shan (1995).
Decision matrices
Let us say that we wish to find the minimal set of consistent rules (logical implications) that characterize our sample system. For a set of condition attributes 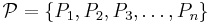 and a decision attribute
and a decision attribute 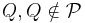 , these rules should have the form
, these rules should have the form 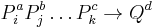 , or, spelled out,
, or, spelled out,

where 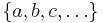 are legitimate values from the domains of their respective attributes. This is a form typical of association rules, and the number of items in which match the condition/antecedent is called the support for the rule. The method for extracting such rules given in Ziarko & Shan (1995) is to form a decision matrix corresponding to each individual value
are legitimate values from the domains of their respective attributes. This is a form typical of association rules, and the number of items in which match the condition/antecedent is called the support for the rule. The method for extracting such rules given in Ziarko & Shan (1995) is to form a decision matrix corresponding to each individual value 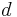 of decision attribute . Informally, the decision matrix for value of decision attribute lists all attribute–value pairs that differ between objects having
of decision attribute . Informally, the decision matrix for value of decision attribute lists all attribute–value pairs that differ between objects having 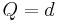 and
and 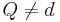 .
.
This is best explained by example (which also avoids a lot of notation). Consider the table above, and let be the decision variable (i.e., the variable on the right side of the implications) and let 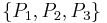 be the condition variables (on the left side of the implication). We note that the decision variable takes on two different values, namely
be the condition variables (on the left side of the implication). We note that the decision variable takes on two different values, namely 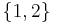 . We treat each case separately.
. We treat each case separately.
First, we look at the case 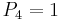 , and we divide up into objects that have and those that have
, and we divide up into objects that have and those that have 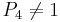 . (Note that objects with in this case are simply the objects that have
. (Note that objects with in this case are simply the objects that have 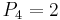 , but in general, would include all objects having any value for other than , and there may be several such classes of objects (for example, those having
, but in general, would include all objects having any value for other than , and there may be several such classes of objects (for example, those having 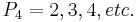 ).) In this case, the objects having are
).) In this case, the objects having are 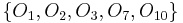 while the objects which have are
while the objects which have are 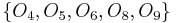 . The decision matrix for lists all the differences between the objects having and those having ; that is, the decision matrix lists all the differences between and . We put the "positive" objects () as the rows, and the "negative" objects as the columns.
. The decision matrix for lists all the differences between the objects having and those having ; that is, the decision matrix lists all the differences between and . We put the "positive" objects () as the rows, and the "negative" objects as the columns.
-
Decision matrix for Object 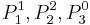
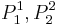
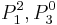
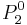
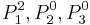
To read this decision matrix, look, for example, at the intersection of row and column , showing in the cell. This means that with regard to decision value , object differs from object on attributes 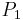 and
and 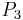 , and the particular values on these attributes for the positive object are
, and the particular values on these attributes for the positive object are 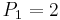 and
and 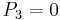 . This tells us that the correct classification of as belonging to decision class rests on attributes and ; although one or the other might be dispensable, we know that at least one of these attributes is indispensable.
. This tells us that the correct classification of as belonging to decision class rests on attributes and ; although one or the other might be dispensable, we know that at least one of these attributes is indispensable.
Next, from each decision matrix we form a set of Boolean expressions, one expression for each row of the matrix. The items within each cell are aggregated disjunctively, and the individuals cells are then aggregated conjunctively. Thus, for the above table we have the following five Boolean expressions:
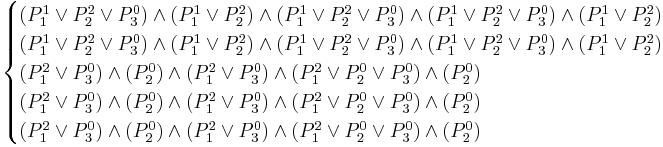
Each statement here is essentially a highly specific (probably too specific) rule governing the membership in class of the corresponding object. For example, the last statement, corresponding to object , states that all the following must be satisfied:
- Either must have value 2, or must have value 0, or both.
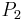 must have value 0.
must have value 0.- Either must have value 2, or must have value 0, or both.
- Either must have value 2, or must have value 0, or must have value 0, or any combination thereof.
- must have value 0.
It is clear that there is a large amount of redundancy here, and the next step is to simplify using traditional Boolean algebra. The statement 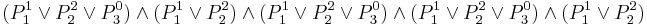 corresponding to objects simplifies to
corresponding to objects simplifies to 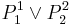 , which yields the implication
, which yields the implication

Likewise, the statement 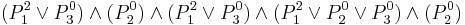 corresponding to objects simplifies to
corresponding to objects simplifies to 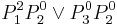 . This gives us the implication
. This gives us the implication

The above implications can also be written as the following rule set:
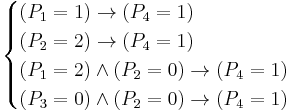
It can be noted that each of the first two rules has a support of 2 (i.e., the antecedent matches two objects), while each of the last two rules has a support of 3. To finish writing the rule set for this knowledge system, the same procedure as above (starting with writing a new decision matrix) should be followed for the case of , thus yielding a new set of implications for that decision value (i.e., a set of implications with as the consequent). In general, the procedure will be repeated for each possible value of the decision variable.
LERS rule induction system
The data system LERS (Learning from Examples based on Rough Sets) Grzymala-Busse (1997) may induce rules from inconsistent data, i.e., data with conflicting objects. Two objects are conflicting when they are characterized by the same values of all attributes, but they belong to different concepts (classes). LERS uses rough set theory to compute lower and upper approximations for concepts involved in conflicts with other concepts.
Rules induced from the lower approximation of the concept certainly describe the concept, hence such rules are called certain. On the other hand, rules induced from the upper approximation of the concept describe the concept possibly, so these rules are called possible. For rule induction LERS uses three algorithms: LEM1, LEM2, and IRIM.
The LEM2 algorithm of LERS is frequently used for rule induction and is used not only in LERS but also in other systems, e.g., in RSES (Bazan et al. (2004). LEM2 explores the search space of attribute-value pairs. Its input data set is a lower or upper approximation of a concept, so its input data set is always consistent. In general, LEM2 computes a local covering and then converts it into a rule set. We will quote a few definitions to describe the LEM2 algorithm.
The LEM2 algorithm is based on an idea of an attribute-value pair block. Let be a nonempty lower or upper approximation of a concept represented by a decision-value pair 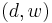 . Set depends on a set
. Set depends on a set 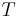 of attribute-value pairs
of attribute-value pairs 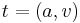 if and only if
if and only if
![\emptyset \neq [T] = \bigcap_{t \in T} [t] \subseteq X.](/2012-wikipedia_en_all_nopic_01_2012/I/a937972009ee96b79d02ad08c20a74de.png)
Set is a minimal complex of if and only if depends on and no proper subset 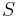 of exists such that depends on . Let
of exists such that depends on . Let 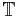 be a nonempty collection of nonempty sets of attribute-value pairs. Then is a local covering of if and only if the following three conditions are satisfied:
be a nonempty collection of nonempty sets of attribute-value pairs. Then is a local covering of if and only if the following three conditions are satisfied:
each member of is a minimal complex of ,
![\bigcup_{t \in \mathbb{T}} [T] = X,](/2012-wikipedia_en_all_nopic_01_2012/I/2b0a7f278881c0a187f304b3ee8d1c45.png)
is minimal, i.e., has the smallest possible number of members.
For our sample information system, LEM2 will induce the following rules:
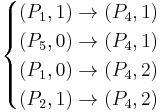
Other rule-learning methods can be found, e.g., in Pawlak (1991), Stefanowski (1998), Bazan et al. (2004), etc.
Incomplete data
Rough set theory is useful for rule induction from incomplete data sets. Using this approach we can distinguish between three types of missing attribute values: lost values (the values that were recorded but currently are unavailable), attribute-concept values (these missing attribute values may be replaced by any attribute value limited to the same concept), and "do not care" conditions (the original values were irrelevant). A concept (class) is a set of all objects classified (or diagnosed) the same way.
Two special data sets with missing attribute values were extensively studied: in the first case, all missing attribute values were lost (Stefanowski and Tsoukias, 2001), in the second case, all missing attribute values were "do not care" conditions (Kryszkiewicz, 1999).
In attribute-concept values interpretation of a missing attribute value, the missing attribute value may be replaced by any value of the attribute domain restricted to the concept to which the object with a missing attribute value belongs (Grzymala-Busse and Grzymala-Busse, 2007). For example, if for a patient the value of an attribute Temperature is missing, this patient is sick with flu, and all remaining patients sick with flu have values high or very-high for Temperature when using the interpretation of the missing attribute value as the attribute-concept value, we will replace the missing attribute value with high and very-high. Additionally, the characteristic relation, (see, e.g., Grzymala-Busse and Grzymala-Busse, 2007) enables to process data sets with all three kind of missing attribute values at the same time: lost, "do not care" conditions, and attribute-concept values.
Applications
Rough set methods can be applied as a component of hybrid solutions in machine learning and data mining. They have been found to be particularly useful for rule induction and feature selection (semantics-preserving dimensionality reduction). Rough set-based data analysis methods have been successfully applied in bioinformatics, economics and finance, medicine, multimedia, web and text mining, signal and image processing, software engineering, robotics, and engineering (e.g. power systems and control engineering).
Extensions
Dominance-based rough set approach (DRSA) is an extension of rough set theory for multi-criteria decision analysis (MCDA), introduced by Greco, Matarazzo and Słowiński (2001). The main change in this extension of classical rough sets is the substitution of the indiscernibility relation by a dominance relation, which permits the formalism to deal with inconsistencies typical in consideration of criteria and preference-ordered decision classes.
Decision-theoretic rough sets (DTRS) is a probabilistic extension of rough set theory introduced by Yao, Wong, and Lingras (1990). It utilizes a Bayesian decision procedure for minimum risk decision making. Elements are included into the lower and upper approximations based on whether their conditional probability is above thresholds 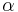 and
and 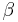 . These upper and lower thresholds determine region inclusion for elements. This model is unique and powerful since the thresholds themselves are calculated from a set of six loss functions representing classification risks.
. These upper and lower thresholds determine region inclusion for elements. This model is unique and powerful since the thresholds themselves are calculated from a set of six loss functions representing classification risks.
History
The idea of rough set was proposed by Pawlak (1981) as a new mathematical tool to deal with vague concepts. Comer, Grzymala-Busse, Iwinski, Nieminen, Novotny, Pawlak, Obtulowicz, and Pomykala have studied algebraic properties of rough sets. Different algebraic semantics have been developed by P. Pagliani, I. Duntsch, M. K. Chakraborty, M. Banerjee and A. Mani; these have been extended to more generalized rough sets by D. Cattaneo and A. Mani, in particular. Rough sets can be used to represent ambiguity, vagueness and general uncertainty. Fuzzy-rough sets further extend the rough set concept through the use of fuzzy equivalence classes.
See also
- Algebraic semantics
- Alternative set theory
- Description logic
- Fuzzy logic
- Fuzzy set theory
- Generalized rough set theory
- Granular computing
- Near sets
- Rough fuzzy hybridization
- Semantics of rough set theory
- Soft computing
- Type-2 fuzzy sets and systems
- Decision-theoretic rough sets
- Variable precision rough set
- Version space
- Dominance-based rough set approach
References
- Pawlak, Zdzisław (1982). "Rough sets". International Journal of Parallel Programming 11 (5): 341–356. doi:10.1007/BF01001956.
- Bazan, Jan; Szczuka, Marcin and Wojna, Arkadiusz and Wojnarski, Marcin (2004). "On the evolution of rough set exploration system". Proceedings of the RSCTC 2004: 592–601.
- Dubois, D.; Prade, H. (1990). "Rough fuzzy sets and fuzzy rough sets". International Journal of General Systems 17 (2–3): 191–209. doi:10.1080/03081079008935107.
- Greco, Salvatore; Matarazzo, Benedetto and Słowiński, Roman (2001). "Rough sets theory for multicriteria decision analysis". European Journal of Operational Research 129 (1): 1–47. doi:10.1016/S0377-2217(00)00167-3.
- Grzymala-Busse, Jerzy (1997). "A new version of the rule induction system LERS". Fundamenta Informaticae 31: 27–397.
- Grzymala-Busse, Jerzy; Grzymala-Busse, Witold (2007). "An experimental comparison of three rough set approaches to missing attribute values". Transactions on Rough Sets 6: 31–50.
- Kryszkiewicz, Marzena (1999). "Rules in incomplete systems". Information Sciences 113 (3–4): 271–292. doi:10.1016/S0020-0255(98)10065-8.
- Pawlak, Zdzisław Rough Sets Research Report PAS 431, Institute of Computer Science, Polish Academy of Sciences (1981)
- Pawlak, Zdzisław; Wong, S. K. M. and Ziarko, Wojciech (1988). "Rough sets: Probabilistic versus deterministic approach". International Journal of Man-Machine Studies 29: 81–95. doi:10.1016/S0020-7373(88)80032-4.
- Pawlak, Zdzisław (1991). Rough Sets: Theoretical Aspects of Reasoning About Data. Dordrecht: Kluwer Academic Publishing. ISBN 0-7923-1472-7.
- Slezak, Dominik; Wroblewski, Jakub; Eastwood, Victoria and Synak, Piotr (2008). "Brighthouse: an analytic data warehouse for ad-hoc queries". Pvldb 1(2): 1337–1345. http://www.vldb.org/pvldb/1/1454174.pdf.
- Stefanowski, Jerzy (1998). "On rough set based approaches to induction of decision rules". In Polkowski, Lech and Skowron, Andrzej. Rough Sets in Knowledge Discovery 1: Methodology and Applications. Heidelberg: Physica-Verlag. pp. 500–529.
- Stefanowski, Jerzy; Tsoukias, Alexis (2001). "Incomplete information tables and rough classification". 17. 545–566.
- Wong, S. K. M.; Ziarko, Wojciech and Ye, R. Li (1986). "Comparison of rough-set and statistical methods in inductive learning". International Journal of Man-Machine Studies 24: 53–72.
- Yao, J. T.; Yao, Y. Y. (2002). "Induction of classification rules by granular computing". Proceedings of the Third International Conference on Rough Sets and Current Trends in Computing (TSCTC'02). London, UK: Springer-Verlag. pp. 331–338.
- Ziarko, Wojciech (1998). "Rough sets as a methodology for data mining". Rough Sets in Knowledge Discovery 1: Methodology and Applications. Heidelberg: Physica-Verlag. pp. 554–576.
- Ziarko, Wojciech; Shan, Ning (1995). "Discovering attribute relationships, dependencies and rules by using rough sets". Proceedings of the 28th Annual Hawaii International Conference on System Sciences (HICSS'95). Hawaii. pp. 293–299.